Canonical tags are an essential tool to prevent duplicate content in organic search results. “Canonical” in search engine parlance means the one true page out of potentially many duplicates.
Canonical tags are single lines of code in the HTML <head> section of a web page. They are invisible to visitors but not to search bots.
Note the example below from Kohl’s, which assigns a canonical tag for a Bedding and Bath sale page.
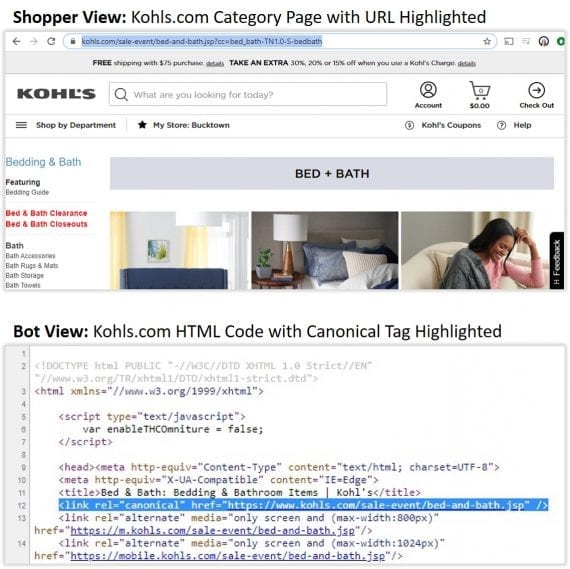
Kohl’s uses a canonical tag on a Bedding and Bath sale page to reduce duplicate content.
How Do Canonicals Work?
When they encounter a canonical tag on a page, search bots compare the URL in the tag to the URL of the page they are crawling. If the URLs match, the page they’re on is the canonical version. If not, the bots will consider not indexing that page and attributing its link authority to the canonical version.
For example, in the image above, the URL in the browser bar for Kohl’s Bedding and Bath sale page is https://www.kohls.com/sale-event/bed-and-bath.jsp?cc=bed_bath-TN1.0-S-bedbath. But the canonical tag identifies a tidier version:
<link rel="canonical" href="https://www.kohls.com/sale-event/bed-and-bath.jsp"/>
Thus search engines will probably index only the version without the parameter (the “?cc=bed_bath-TN1.0-S-bedbath”).
How to Implement
Most ecommerce platforms include self-referencing canonical tags by default. A page at https://www.site.com/cat/prod-123.jsp would have a canonical tag that contains its own URL:
<link rel="canonical" href="https://www.site.com/cat/prod-123.jsp"/>
But there are many ways that an ecommerce site spawns duplicate content. For https://www.site.com/cat/prod-123.jsp, duplicate pages could include:
- Tracking parameters: https://www.site.com/cat/prod-123.jsp?source=123,
- Different click paths to products that produce different URLs: https://www.site.com/cat/subcat/prod-123.jsp,
- A duplicate subdomain: https://shop.site.com/cat/subcat/prod-123.jsp.
- Unfriendly system-generated URLs: https://www.site.com/en/shop/c-ABC/p-123.jsp
We can ask search engines to ignore those four duplicate pages by inserting the same canonical tag into each page, which, again, is:
<link rel="canonical" href="https://www.site.com/cat/prod-123.jsp"/>
Your ecommerce platform may enable you to modify canonical tags for each page as easily as changing a title tag. However, the best option is to manage canonical tags programmatically, which likely involves a developer.
Canonical tags can also manage syndicated content that appears on multiple sites. The words determine duplicate content, not the design or the font. Similarly, excerpts posted on one site that link to a full version on another are duplicate content.
Absent a canonical tag, search engines will choose which page to rank based on which was posted first, which has more links, or another algorithmic method. To properly assign rank, use canonical tags and obligate syndication partners to use them, too.
Other Options
There are three additional ways beyond tags to specify canonical URLs: in the XML sitemap, in HTTP headers, and with a 301 redirect.
XML sitemaps list the URLs on your site that you want search bots to crawl. Done right, XML sitemaps are effective in delivering canonical URLs. Unfortunately, many sites fail to execute sitemaps correctly or fail to note noncanonical URLs, leaving search engines to make the association of duplicate pages on their own.
PDF files and other file formats that do not contain HTML source code can indicate a canonical URL in the HTTP header. For example, say you have the same text on a web page and a PDF file. You want the web page to rank because it contains your site’s navigation and calls to action. To do this, place a self-referencing canonical tag in the page, such as:
<link rel="canonical" href="https://www.site.com/cat/prod-123.jsp"/>
Then, to prevent the PDF from ranking, use the page’s URL in the HTTP header’s link tag when the server delivers the PDF file:
link: <https://www.site.com/cat/prod-123.jsp>; rel="canonical"
The syntax is different — though the elements are similar — because one is a meta tag in HTML code and the other is a statement in an HTTP header.
Remember that canonical tags are only recommendations. Search engines will decide which page will be the canonical version based, again, on relevance and authority signals. You can view the canonical page for any URL you’re verified to access in Google Search Console using the URL Inspection tool.
A more forceful solution for removing duplicate content is a 301 redirect. This powerful canonicalization tool commands search engines to (i) de-index the URL, (ii) request indexing for the new URL, (iii) and associate the old page’s link authority to the new one. Unlike a canonical tag, a 301 is a command rather than a suggestion.
For more, see “SEO: 7 Ways to Kill Duplicate Content,” my post from last year.