Knowing the breadcrumb navigation of your ecommerce competitors can be helpful. It could identify missing categories on your own site, navigation ideas, and even competitors’ best-selling products.
At the recent SMX West conference in San Jose, Arsen Rabinovich from the agency TopHatRank shared a technique using Screaming Frog to extract breadcrumb structure from any site.
I’ll explain his process in this article.
Extracting Breadcrumbs
To illustrate, I’ll extract breadcrumbs from two competitors: Pier 1 Imports and Kirkland’s, a home decor retailer.
To start, I’ll locate a product page on Pier 1 — “Kubu Armless Dining Cushion in Natural” — and visually check for the breadcrumbs.
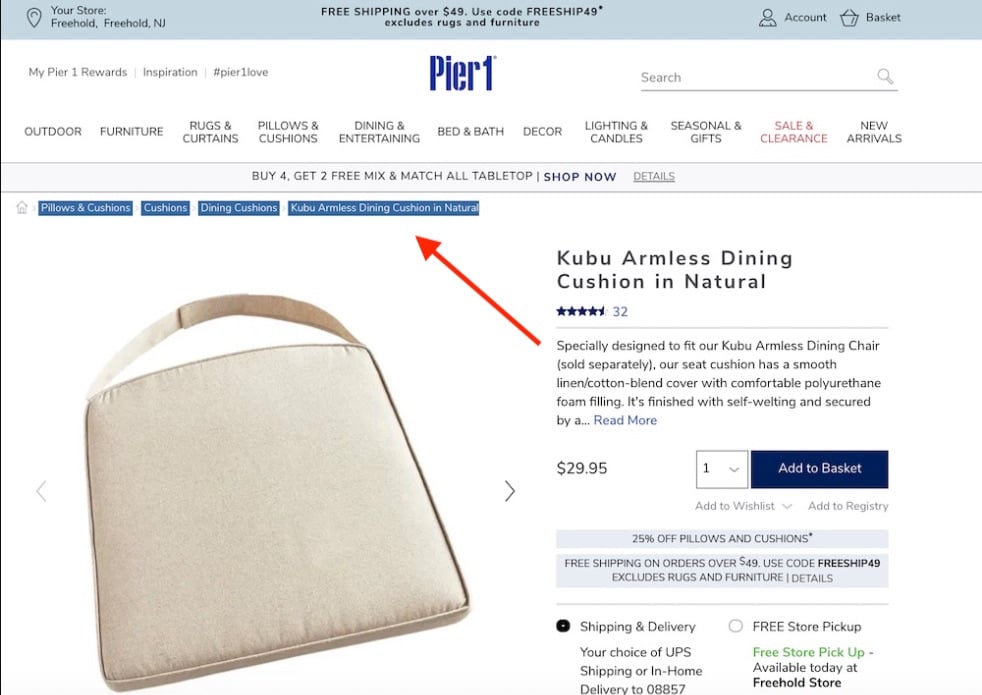
Locate a product page on Pier 1, such as “Kubu Armless Dining Cushion in Natural,” and visually check for the breadcrumbs.
Next, I’ll use Google’s Structured Data Testing Tool to see if Pier 1 marked up the breadcrumbs with structured data. The answer is yes! Breadcrumbs are nicely formatted.
However, having tested the product “White Letter Peg Board with Black Letters,” I see that Kirkland’s does not use structured data. But it doesn’t matter. We can still extract Kirkland’s breadcrumbs with Screaming Frog.
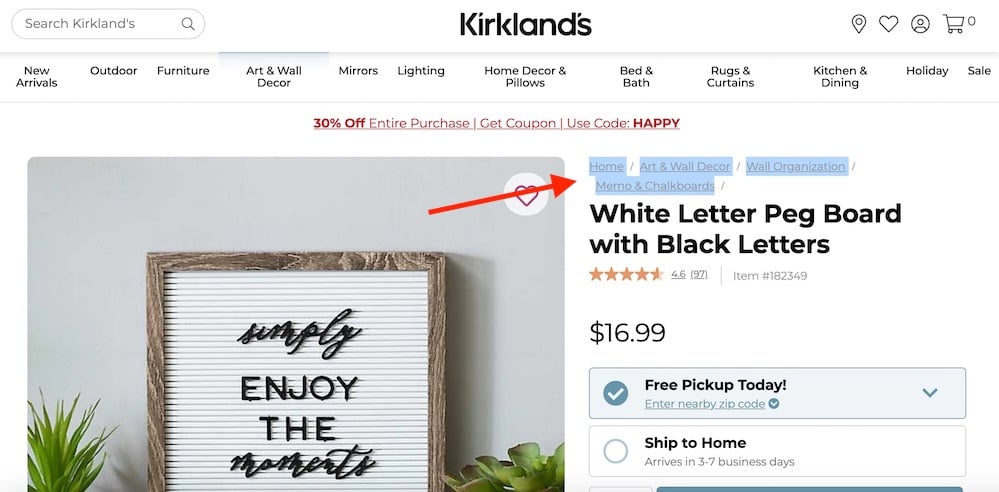
Kirkland’s does not use structured data for its breadcrumb, as confirmed by testing the “White Letter Peg Board with Black Letters” product page.
Pages to Scrape
I will use Screaming Frog to crawl the product pages from both Pier 1 and Kirkland’s. Since both sites provide product-only XML sitemaps in the robots.txt file, this is relatively simple. For example, the index sitemap for Pier 1 is https://www.pier1.com/sitemap_index.xml. It includes two product sitemaps. The first is https://www.pier1.com/sitemap_0-product.xml.
Kirkland’s doesn’t include an index sitemap. But it does have a products’ sitemap: https://www.kirklands.com/product_sitemap.xml.
Extracting Structured Data
To start, I’ll use Screaming Frog’s tool for extracting and validating structured data.
First, I will select in Screaming Frog the structured data format used by Pier 1 — microdata. JSON-LD and RDFa are other popular formats supported by Google, Bing, and other search engines.

Select the structured data format used by Pier 1 — microdata — in Screaming Frog’s tool for extracting and validating structured data. Click image to enlarge.
When I tried to scrape Pier 1 using Screaming Frog, however, I was limited to five URLs because the site blocks automated crawls. Thus I downloaded Pier 1’s XML sitemap and directed Screaming Frog to read it locally.
From there, I will export the data from Screaming Frog. Fortunately, there is a handy report in Screaming Frog to download all URLs.

Export the URLs in Screaming Frog. Click image to enlarge.
This is what the exported breadcrumbs look like after you filter on the column “predicate” for the value “http://schema.org/name.” I also included only subjects 2, 3, 4, 5, and 6 as these include the breadcrumb names.

Exported breadcrumbs in Screaming Frog after filtering on the column “predicate” for the value “http://schema.org/name.” Click image to enlarge.
Extracting Unstructured Data
Extracting Kirkland’s breadcrumbs it is not as simple since there’s no structured data. But we can define custom extraction rules to obtain them.
First, I will right-click (in Chrome) on a breadcrumb link and select “copy JS path” in the “Inspect Elements” tab in Chrome’s developer tools. You can copy and paste them into the JavaScript Console tab to verify they work.

Right-click on a breadcrumb link and select “copy JS path” in the “Inspect Elements” tab in Chrome’s developer tools. Click image to enlarge.
Here is my verified list from Chrome. Be sure to choose the CSSPath option and “Extract Inner HTML.”

For the verified list from Chrome, choose the CSSPath option and “Extract Inner HTML.” Click image to enlarge.
To test in Screaming Frog, select “Enter Manually” in the Upload options. Then provide only one product URL. When I first tested this, all the custom extraction columns were empty — they were generated dynamically using JavaScript.
To fix, select “JavaScript” in the configuration under “Rendering.”
Now we have Kirkland’s breadcrumbs! We need additional clean-up (in Excel) as the extraction also pulled image tags.
Recommended

Remembering Hamlet Batista
February 8, 2021
Navigational Structure
I can now review the navigational structure of both sites. I’ll use Pier 1 for this example. Kirkland’s would be similar, however.
Using Excel, I’ll create a pivot table with the columns “URL,” “Subject,” “Predicate,” and “Object.” (I renamed “Object” to “Breadcrumb.”)
Move the “Breadcrumb” field to the “Rows” box, the “URL” to “Values” and “Subject” to “Columns.”
In looking at the screenshot below, we can infer Pier 1’s site hierarchy by reviewing the numbers in the columns subjects 2, 3, 4, and 5. Home is 7. We have two nodes in subject 3 with counts 4 and 3. Those nodes are Furniture and Outdoor. The numbers represent the number of URLs in each category.

Create a pivot table in Excel. Click image to enlarge.
We could perform the same analysis for any ecommerce site. Doing so would provide a visual of its navigation.